
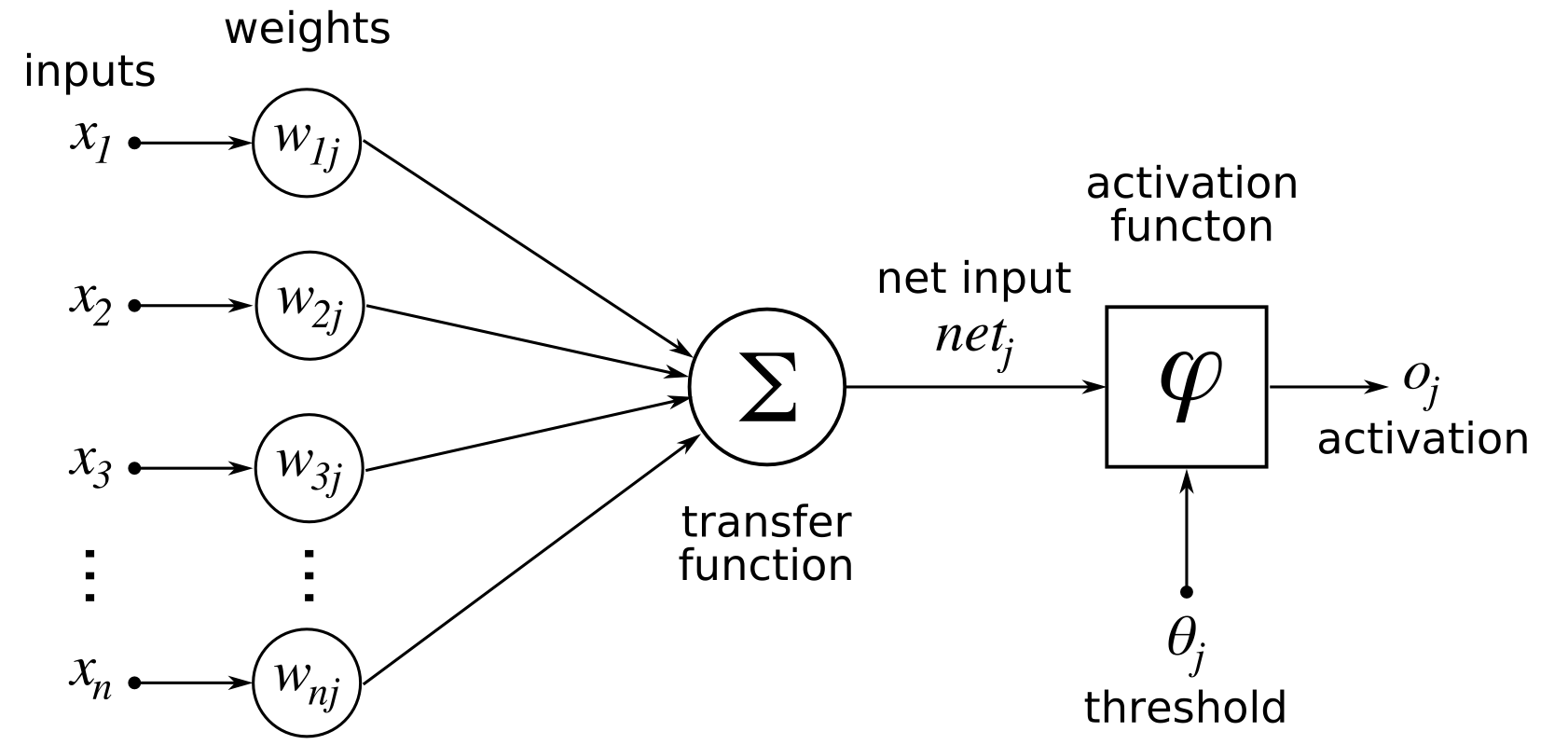
The activation function neural networks calculate a weighted number and then adds bias to it to determine if a neuron must be stimulated or not. The activation function’s goal is to inject non-linearity into the neuron’s output.
Components of a neural network
The input layer embraces functionality from the user. It feeds the network information about the outer world. No processing is needed here; networks transfer the features (information) on the secret layer.
This layer’s nodes aren’t visible to the outside world; they’re part of an abstraction that every neural network provides. The hidden layer computes all of the functionality entered via the input nodes and sends the results to the output nodes.
Output Layer
This layer communicates the network’s acquired knowledge to the outside world.
We understand that neurons in a neural network behave by their weight, bias, and activation mechanism. We will change all the neurons’ weights and biases in a human brain based on the output error.
Backpropagation is the term for this method. Because the contours are provided, including the error to modify the weights and biases, the activation function neural networks allow backpropagation. These involve:
- Activation properties
- Non-linearity
- Range

Activation Function Variants
Linear Equation
The equation of a linear function is identical to that of a straight line, i.e., y = ax.
If all of the layers are linear in design, the actual artificial neuron of the last surface is nothing more than a periodic combination of the first layer’s input.
The linear input layer has one usage in the output layer.
Issues
If we distinguish a linear function and add non-linearity, the output will no longer be dependent on the input “x.” The feature will be constant, so the algorithm will not exhibit any novel behavior.
Example:
The measurement of a building’s price is a linear equation. Since the price of a house can be either large or small, we can use linear activation at the output layer. Even in this case, some nonlinear feature at the hidden layers of the activation function neural networks is essential.
Sigmoid Function
This function graphs as an ‘S’ form. A = 1/(1 + e-x) equation
Nature
The X values range from -2 to 2, while the Y values are extremely steep. This implies that minor differences in X can result in significant changes in Y’s value.
0 to 1 is the value range.
Uses
The sigmoid function is present in the output nodes of a classification problem, where the outcome is either 0 or 1.
Since the sigmoid function’s value lies between 0 and 1, the expected results to be one of the inputs higher than 0.5 or 0 instead.
Tanh Function
Tanh function, also known as the Tangent Hyperbolic component, is an action that almost often outperforms the sigmoid function. It’s essentially a sigmoid function, further mathematically shifted. Both of these relate to one another and can deduce from one another.
Uses
Generally used in hidden units of a genetic algorithm when its values range from -1 to 1, causing the hidden layer’s mean to be 0 or very near to it, which aids in data centering by having the mean close to 0. This makes mastering the next layer even more straightforward.
A(x) = maximum equation (0,x). If x is positive, it returns x; otherwise, it returns 0.
[0, inf) Value Range
Nature is nonlinear, which means we can quickly backpropagate errors and make the ReLU mechanism cause different layers of neurons.
Since it requires fewer arithmetic computations, ReLu becomes less computationally costly than Tanh and sigmoid. Just a few activation function neural networks stimulate at a time, making the network small and effective for computation.
Simply put, the RELU function learns much better than the sigmoid and Tanh functions.
Softmax Function
A softmax function is a kind of sigmoid function that comes in handy when dealing with classification issues.
Uses
This is common when dealing with different grades. The softmax function will multiply by the outputs and compress the outcomes for every class around 0 & 1.
Result
The softmax function is best used in the classifier’s output layer, where we’re attempting to determine the classification of every input using probabilities.
Activation function neural networks fundamentals
If you don’t know what activation function to use, the simplest rule of thumb is RELU. It is a common activation function present in most situations these days.
The sigmoid function is a normal alternative for the output layer if the output would be for binary classification.
The design of neural networks is close to that of the human brain, made up of neurons. The chemical inputs (X1, X2) and weights (W1, W2) are added along with bias(b) and afterward acted on by an activating function (f) to produce the output (y).
The activation mechanism in such a neural network is the most crucial element. It helps determine whether such a neuron can stimulate and transport to the next level.
This means that it will determine if the neuron’s feedback to a network is important or not during the prediction process.
As a result, the neurons that may converge the network are often alluded to as thresholds or transitions.
Activation functions aid in the normalization of operation from 0 to 1 or -1 to 1. Due to the differentiable property, it aids in the backpropagation procedure.
The loss function is modified during backpropagation, and the activation function aids the neural network curves in reaching their local minima.

Linear
The simplest activation function is linear, which means proportional to the data. The formula Y = az is identical to the straight-line equation.
From -inf to +inf, this function returns a number of activations. This form of method is best for regression analysis problems, such as predicting house prices.
Merits
Since the linear function’s derivative is constant(a), there is no relationship between input and output.
As a result, it isn’t the best option because it won’t help with backpropagation to rectify the gradient & loss functions.
ReLU
In the hidden units of a deep learning algorithm, the Rectified Linear Component is the most commonly used activation function.
The formula is straightforward: unless the value is positive, the number is returned; otherwise, 0.
As a result, the function is also straightforward, with 1 for true traits and 0 otherwise. As a result, the shortest path problem resolves. 0 to infinity is the length.
Deficiencies
Whenever the variable is 0, and the weights are not modified, the issue of dying ReLU or broken activation arises. Other than secret layers, it can’t be seen.
The decreasing ReLU is no longer a challenge with the Exponential Linear Unit. Except for the negative values, it’s very close to ReLU.
If the coefficient is greater, this method takes the same value; otherwise, it returns alpha (exp(x) – 1), while alpha is a small integer.
For positive values, the derivative is 1, and for negative values, it results from alpha & exp(x). 0 to infinity is the length. It is centered on empty.
Merits
ReLU does have the property of being smooth over time, which will significantly increase the activation function. Because of the exponential equation, it is more computationally costly than ReLU.
ReLU has a variant called LeakyReLU. It is the same as ReLU for true traits, returning the same input, and a steady 0.01 with activation function is given for other values. This is done to resolve the dying ReLu issue. If the derivative is positive, it is 1; otherwise, it is 0.01.
You cannot see this in complex problems like grouping because of its linearity.
PRELUDE
The Parameterized Rectified Unit is a variant of the ReLU and LeakyReLU that computes negative values as alpha*input. Unlike in Leaky ReLU, where the alpha value is 0.01, in PReLU, the alpha value is learned by backpropagation by putting various values, resulting in the best learning process.
Sigmoid
The sigmoid activation function is just a nonlinear objective function. The Logistic function is another name for it. It is monotonous and constant. The production converts to a value between 0 and 1. It has a flat gradient curve and is differentiable. In binary classification, sigmoid one uses sigmoid before the reference sheet.
Merits
The problem is disappearing gradient but not zero centric, making optimization more difficult. Learning slows down due to this.
SIREN
(Sinusoidal Representation Systems for Implicit Neural Representations) is an acronym for Sinusoidal Representation Networks with Implicit Neural Representations.
The value of the nonlinear activation function varies from -1 to 1, and the derivative values vary from 0 to 1. It is centered on empty. It outperforms the sigmoid. For secret layers, their uses are necessary for binary classification.
Softmax
As an output, the Softmax activation method contains probabilities of the inputs. Probabilities will help determine the goal class. The performance with the greatest likelihood would be the final product. Both of these odds would add up to one. During classification problems, particularly multiclass classification, you can use this.
Softmax would not function on data that is linearly separable.
Swish
Swish is a ReLU feature of some kind. It’s a self-grated function that only needs input and doesn’t need any other parameters. y = x * sigmoid is a formula (x). LSTMs are the most popular use. It’s zero-centric and solves the dilemma of dead activation. It has a smoothness to it that aids generalization and optimization.
Merits
It needs a lot of processing power and is used where the genetic algorithm seems to have more than 35 layers.
It is mathematically impossible to find the derivative of zero. Due to this problem, most artificial neurons have stopped at some stage. The soft plush activation mechanism can solve this. y = ln (1 + exp(x)) is a formula. It’s comparable to ReLU. In nature, it’s smoother. The value can be somewhere between 0 and infinity.
Deficiencies
Softplus will blow up action potentials to a much greater degree due to its lightness and unboundedness.
Sigmoid Activation Function Problem
The Problem of Disappearing Gradients
The biggest issue regarding artificial neural networks is that while they spread back across the network, the gradient decreases significantly. By the time it enters layers close to the model’s input, the error may be so slight that it has no impact. As a result, this issue names as the “vanishing gradients” problem.
The weights and preferences of the early layers do not change accurately with each training program if the gradient is minimal. Since these first layers are always critical for understanding the key components of the data input, they can contribute to total network inaccuracy.
Gradients that explode
High error patterns aggregate and result in some very large changes to neural network-based weights during testing, known as exploding gradients. As a result of these massive updates, the network becomes unreliable. Weight values will become so high that they overflow or result in NaN values if taken to an extreme. ReLU stands for Rectified Linear Units.
According to the shortest path problem, the sigmoid & nonlinear activation training algorithm could be used in domains of several layers. The shortest path problem solves the linear activation function, allowing prototypes to improve quicker and perform better.
For constructing multilayer Perceptron & convolutional neural networks, the linear activation is indeed the default activation.
Final Thoughts
Activation functions determine the performance of a neural network model, which are mathematical equations. Activation functions have a significant impact on the ability of neural networks to converge and the pace at which they do so. In some situations, activation functions can also preclude neural networks from converging in the first place.
The activation mechanism aids in normalizing any input-output in the range of 1 to -1 and 0 to 1.
Since neural networks work on large data sets, the activation mechanism needs to be effective and minimize computation time.


